Please note – The CAIRSS blog has relocated to http://cairss.caul.edu.au/blog
The idea
A short time ago CAIRSS was approached by a Repository Manager from within the CAIRSS community to assist with exporting the contents of their repository to a spreadsheet. It was made apparent that accomplishing this task would greatly assist with Institutional Repository management tasks and most importantly ERA related work.
The tools
There are many ways that data can be extracted, moved and converted. The wisest choice is to use tools that are interoperable. An example of this would be choosing OAI-PMH to extract data rather than attempting to communicate with an individual Repositories data storage device or database etc.
The solution
Our CAIRSS Technical Officer Tim McCallum has completed a solution to address this task in the form of a Java Web Application. FoREveR – Flexible Repository Export Reporter.
Extracting the data
The data extraction is carried out using an OAI-PMH harvester. In this instance The Fascinator was used to accomplish this task. With regards to recent trends in Institutional Repository development and the use of SOLR the next step was an easy choice; simply extract the data from The Fascinator using a SOLR query. As an added bonus SOLR is able to supply the data in JSON (JavaScript Object Notation) format.
Converting the data
Overview
After testing different methods of converting the data including XSLT and Python some research was done revealing some excellent JSON libraries written in Java. The final choice was Java given the fact that the JSON libraries could meet the requirements for this application and that OAI-PMH, The Fascinator and SOLR were all already written in Java.
Technical
The JSON data returned is the result of an HTTP request (can be set to fetch all by default). This data is converted to Java Maps and Java ArrayLists for further processing. The application loops through every record that has been returned and creates a Java Set (unique list/master list). This Set is then displayed in the users browser. This is a last minute chance to select or deselect metadata before the final report is written. It is sometimes the case that a metadata field containing a large amount of content is best left out, as this can make the spreadsheet unmanageable from an end users perspective.
Reporting the data
Once approved the application creates an HTML file with all data saved to a table. The table includes table headings, table rows, table data cells and unordered lists for repeating information. This file can be opened in Microsoft Excel and Open Office spreadsheet applications or viewed in a browser.
Screen Shots
Optional SOLR Query
 Note: It is not necessary to know SOLR query syntax, the application can be set to get everything by default. This may be an area to address with the community and feedback is welcome.
Note: It is not necessary to know SOLR query syntax, the application can be set to get everything by default. This may be an area to address with the community and feedback is welcome.
Feedback

Small sample of spreadsheet output
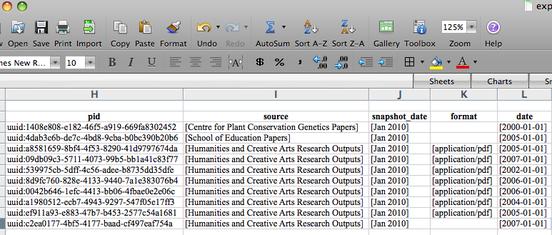
Using the Flexible Repository Export Reporter (FoREveR)
As this software is in the very early stages of its life cycle reports can be created by CAIRSS and emailed out to you. Please contact CAIRSS Central if you think that your institution can benefit from the use of this tool.
The source code is available at http://cairss.caul.edu.au/trac/browser/code/FoREveR for your interest, however it has not been extensively tested. All feedback is welcome. CAIRSS will endeavor to improve and enhance the software to meet your needs.

This sounds like the answer to one of my ongoing concerns which is how to extract from another repository the publication details for a specific author. This is needed when an academic moves from one institution to another and you want a complete set of their publications in your own IR in order to meet ERA reporting as well as to support the author’s generation of a complete bibliography. Is this a valid use of this tool?
Comment by Vanessa Barrett — 2010/01/20 @ 5:48 pm
Hi Tim,
This looks a relly useful little tool. Your DSpace users may also like to know that in version 1.6 which is due for release in the next few week we have a new CSV/Excel/Spreadsheet import + export tool.
As well as allowing the export and import of metadata, it allows for powerful batch editing using the features available in spreadsheet packages such as spellcheck, find and replace, etc.
Thanks,
Stuart
Comment by Stuart Lewis — 2010/01/20 @ 6:32 pm
Hi Vanessa
We may be able to add additional functionality to this application that allows a more granular approach to the reporting tool. Off the cuff I am thinking of an additional Java class that can filter records based on a match for a given author or more specifically the contents of a given facet. From here we may be able to gather further information in a format that is able to be ingested into a given repository if that is what is required. While migrating a set of records from one Repository solution to another is not out of the question, I would have to consult the CAIRSS senior advisor Peter Sefton in order to discuss the particulars. There may be issues with data normalization and the conversion from a metadata harvest (in this case OAI-PMH) and the target Repository software ingest mechanism.
Thank You for your feedback, any further elaboration on this topic are welcome.
Regards
Tim
Comment by tpmccallum — 2010/01/20 @ 8:19 pm
I had just received a request from our Business School to get the publication details for a new member of staff. They wanted to load the publications details into our repository (AR&S) so that this staff member could take advantage of our author publications list to embed in their staff directory page. (e.g. http://digital.library.adelaide.edu.au/cgi-bin/author?author=valenzuela,+ernesto ) The staff member in question came from another University that had an Institutional Repository but which did not offer any ability to download data re publications.
This seemed like the perfect test case and so I worked with Tim through several iterations and now have a spreadsheet of the staff member’s publications so that I can easily import all publications into our repository.
I should point out that all the work was done by Tim. All I did was offer a few suggestions regarding formatting of the data.
This output is only the metadata and does not contain any attachments or files. But this is fine as I would not be able to import files from another repository without some kind of individual moderation.
This tool has huge potential not only for this type of data sharing but also locally to enable more straight forward reporting for operational needs. By doing an OAI harvest and then storing locally you effectively have a data warehouse that you then use for all sorts of reporting, data checking etc.
I have not used the tool myself as Tim carried out all the work in harvesting and then reporting but I will be asking our systems people to investigate using this locally to enable easier ad hoc reporting about data.
Vanessa Barrett
Digital Services Librarian
The University of Adelaide, AUSTRALIA 5005
Comment by caulcairss — 2010/02/02 @ 11:48 am